Free Trial
Web API version
Licensing
Request A Quote
HAVE QUESTIONS OR NEED HELP? SUBMIT THE SUPPORT REQUEST FORM or write email to SUPPORT@BYTESCOUT.COM
Correction to Deal with Date Issue after OCR | VB.NET
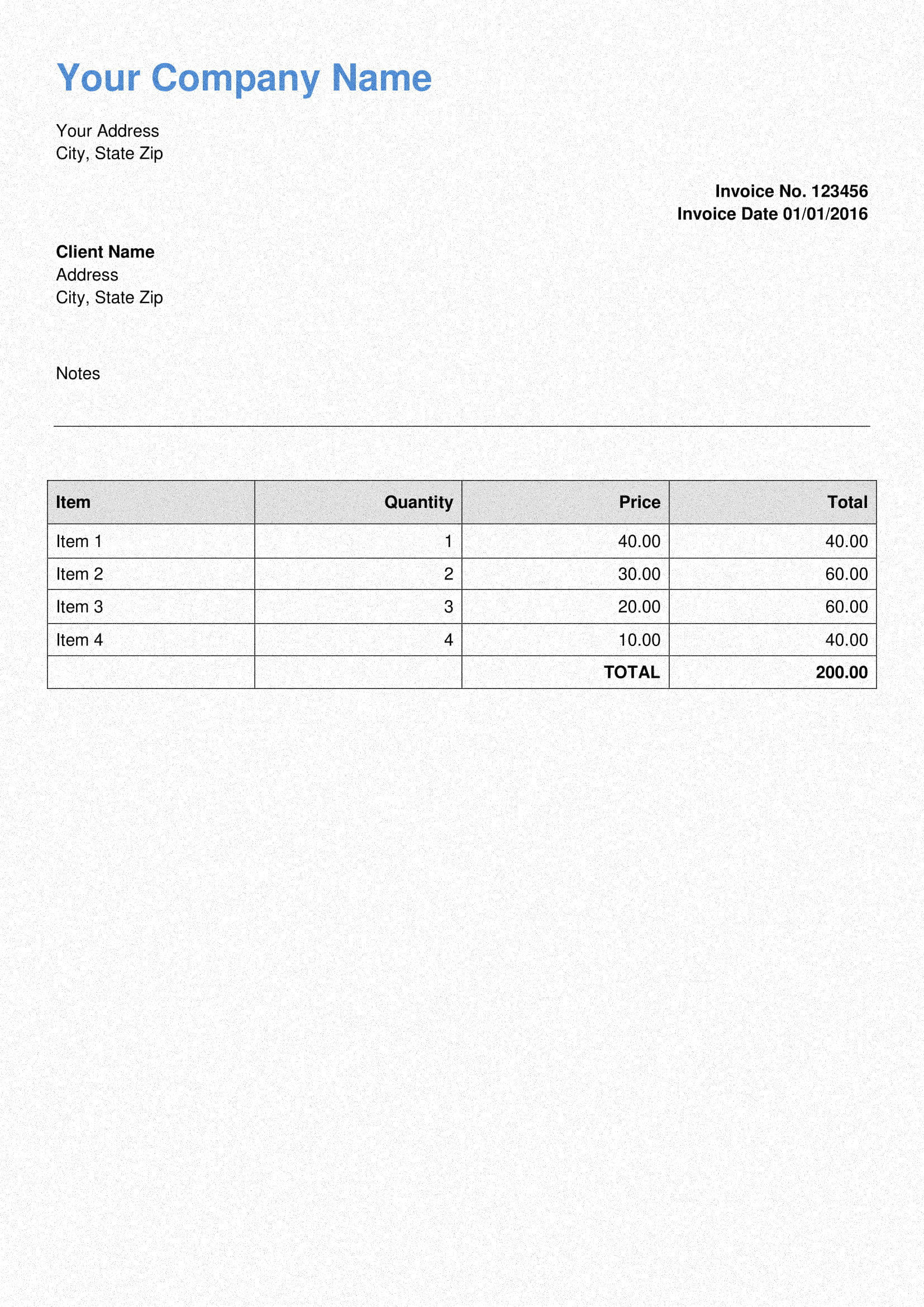
Program.vb:
VB
Imports Bytescout.PDFExtractor ' This example demonstrates the use of Optical Character Recognition (OCR) to extract text ' from scanned PDF documents and raster images. ' To make OCR work you should add the following references to your project: ' "Bytescout.PDFExtractor.dll", "Bytescout.PDFExtractor.OCRExtension.dll". Class Program Friend Shared Sub Main(args As String()) ' Create Bytescout.PDFExtractor.TextExtractor instance Dim extractor As New TextExtractor() extractor.RegistrationName = "demo" extractor.RegistrationKey = "demo" ' Load sample scanned document extractor.LoadDocumentFromFile("InvoiceWithNoise.png") ' Enable Optical Character Recognition (OCR) ' in .Auto mode (SDK automatically checks if needs to use OCR or not) extractor.OCRMode = OCRMode.Auto ' Set the location of OCR language data files extractor.OCRLanguageDataFolder = "c:\Program Files\Bytescout PDF Extractor SDK\ocrdata_best" ' Set OCR language extractor.OCRLanguage = "eng" ' "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in "ocrdata" folder ' Find more language files at https://github.com/bytescout/ocrdata ' Set PDF document rendering resolution extractor.OCRResolution = 300 ' Add profiles to fix issues with date. ' To deal with wrong V in dates you can use a regular expression. The following will replace only V characters which are located between numbers: extractor.LoadProfiles("profiles.json") extractor.Profiles = "ocr-dateIssue" ' Save extracted text to file extractor.SaveTextToFile("output.txt") ' Cleanup extractor.Dispose() ' Open output file in default associated application System.Diagnostics.Process.Start("output.txt") End Sub End Class