Free Trial
Web API version
Licensing
Request A Quote
HAVE QUESTIONS OR NEED HELP? SUBMIT THE SUPPORT REQUEST FORM or write email to SUPPORT@BYTESCOUT.COM
Recognize Text From Document | C#
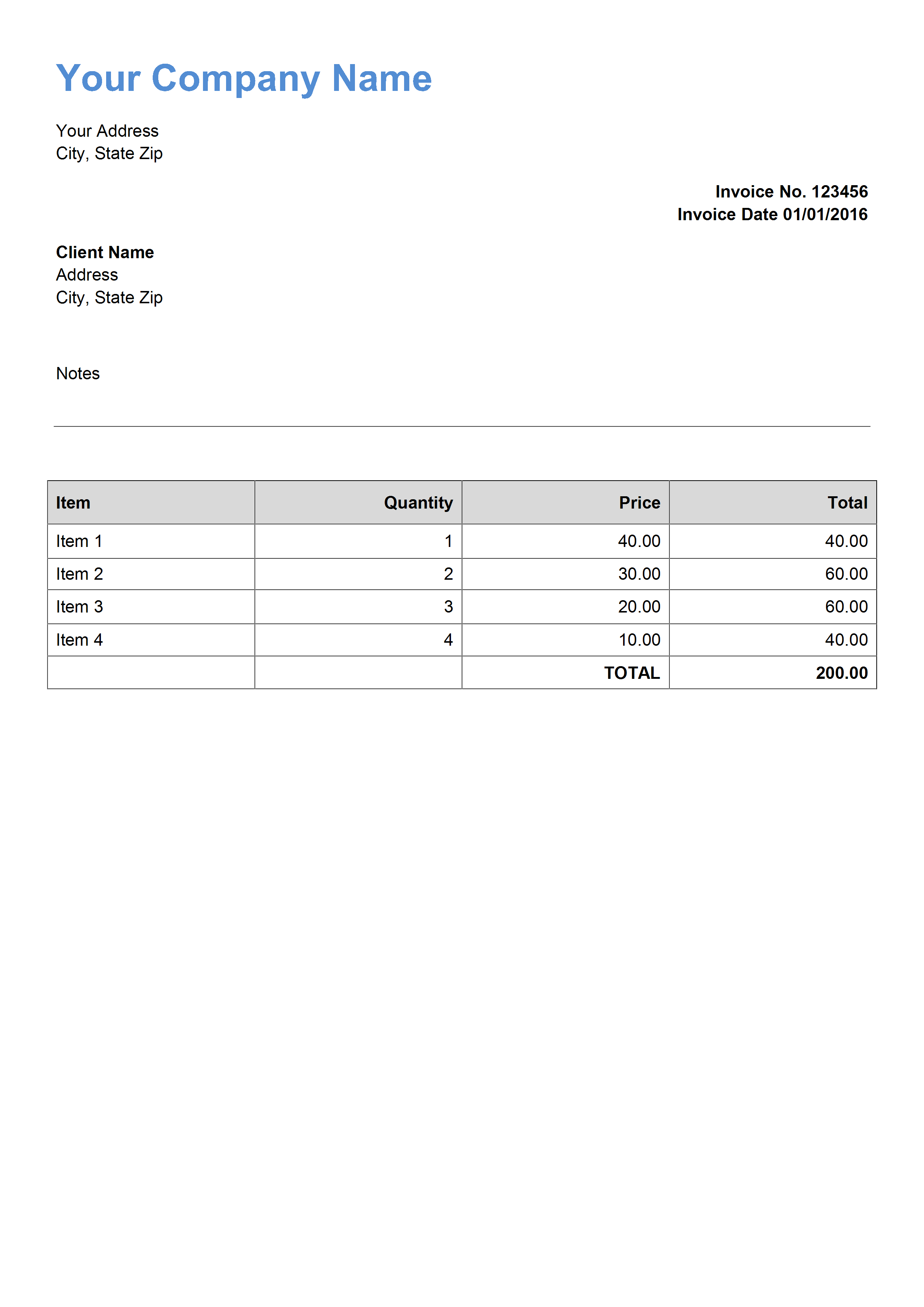
Program.cs:
C#
using System; using System.Diagnostics; using ByteScout.TextRecognition; namespace TextRecognitionExample { class Program { static void Main(string[] args) { string inputDocument = @".\invoice-sample.png"; string outputDocument = @".\result.txt"; // Create and activate TextRecognizer instance using (TextRecognizer textRecognizer = new TextRecognizer("demo", "demo")) { try { // Load document (image or PDF) textRecognizer.LoadDocument(inputDocument); // Set the location of OCR language data files textRecognizer.OCRLanguageDataFolder = @"c:\Program Files\ByteScout Text Recognition SDK\ocrdata_best\"; // Set OCR language. // "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish, etc. - according to files in "ocrdata" folder // Find more language files at https://github.com/bytescout/ocrdata textRecognizer.OCRLanguage = "eng"; // Recognize text from all pages and save it to file textRecognizer.SaveText(outputDocument); // Open the result file in default associated application (for demo purposes) Process.Start(outputDocument); } catch (Exception exception) { Console.WriteLine(exception); } } Console.WriteLine(); Console.WriteLine("Press any key..."); Console.ReadKey(); } } }